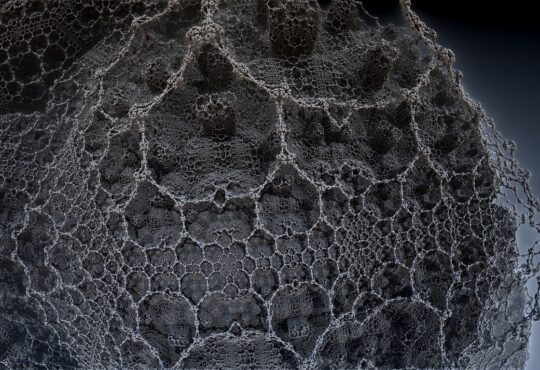
Una rete neurale per le nanoscienze
Grazie all'addestramento di una rete neurale un team di ricercatori è riuscito a produrre un software che aiuterà a classificare e a schedare nanostrutture e nanoparticelle. Il lavoro vede un importante contributo italiano ed è uscito sulla rivista Scientific Report.

TRIESTE CITTÀ DELLA SCIENZA – Tutti noi sappiamo distinguere un tavolo da una sedia, ma sono molti meno quelli che sanno distinguere tra loro diversi tipi di nanoparticelle. Tuttavia, vedendone diverse, dopo un po’ potremmo riuscire distinguere anche noi le categorie principali. Se ciò vale per gli essere umani, può valere anche per un calcolatore? E quale è il modo più efficiente per ottenere questo risultato? La risposta è stata fornita da un team di ricercatori basati in Italia e Gran Bretagna ed è stata presentata in un articolo pubblicato il 16 ottobre sulla rivista Scientific Report. Il team, infatti, è riuscito ad allenare un particolare tipo di programma, una cosiddetta rete neurale, a riconoscere in maniera efficace le immagini di nanoparticelle e nanostrutture ottenute attraverso il microscopio elettronico a scansione. Questa funzione verrà implementata all’interno del progetto internazionale NFFA Europe (Nanoscience Foundries & Fine Analysis) che si occupa di coordinare la ricerca nelle nanoscienze tra vari paesi europei, tra cui l’Italia, semplificando la vita agli scienziati e migliorando la qualità della ricerca.
Le tecniche di riconoscimento immagini sono entrate nella nostra vita da qualche anno e si stanno facendo sempre più sofisticate. Non erano però mai state applicate per oggetti della grandezza dell’ordine dei nanometri, che costituiscono il campo di ricerca e sviluppo delle nanoscienze, un campo che trova applicazioni sempre più numerose che vanno dalla progettazione di nuovi materiali fino alla medicina. Questo risultato è il frutto della collaborazione di diversi enti di ricerca inglesi e italiani tra cui CNR-IOM (Istituto di Officina dei Materiali), la SISSA (Scuola Internazionale Superiore di Studi Avanzati) e l’eXact-Lab, tutti basati a Trieste.
Abbiamo intervistato Rossella Aversa, una delle guide del progetto, per avere maggiori chiarimenti su cosa sia una rete neurale, che cosa significa allenarla e quali sono i risultati e le applicazioni della ricerca appena pubblicata.
Rossella Aversa, un PhD in astrofisica, ma ora una pubblicazione su Scientific Report in un campo completamente diverso.
In realtà, finito il dottorato, ho preso un master in High Performance Computing organizzato in maniera congiunta dalla SISSA e dall’ICTP e attualmente sto facendo un post doc allo CNR-IOM, l’Istituto di Officina dei Materiali. In generale mi occupo di sviluppo di reti neurali per la gestione dati all’interno del progetto NFFA Europe. Si tratta di un progetto internazionale il cui obbiettivo principale è coordinare la ricerca nelle nano scienze tra i 20 enti di ricerca che ne fanno parte e agevolare l’accesso ai dati sia per la scienza che per l’industria. A questo fine assume un ruolo molto importante l’implementazione e lo sviluppo di un data repository, ovvero una sorta di indice generale su tutti i dati che si hanno disposizione nelle banche dati dei vari enti di ricerca, sia che siano il frutto di esperimenti veri e propri sia che provengano da simulazioni teoriche. Un data repository efficiente è fondamentale e in sua mancanza si correrebbe il rischio di avere grandi quantità di dati immagazzinati, ma di fatto difficilmente utilizzabili. Nella fattispecie quel che faccio io è applicare gli algoritmi di apprendimento automatico (machine learning) alle immagini ottenute attraverso il microscopio elettronico a scansione, un particolare tipo di microscopio che sfrutta fasci di elettroni per ottenere immagini molto dettagliate di strutture che arrivano fino alle dimensioni di pochi nanometri. Attraverso ciò contribuisco alla creazione di questo data repository per le nanoscienze e alla programmazione per la gestione dei dati.
Hai detto che lavori presso lo CNR-IOM. Di cosa si occupa?
L’Istituto Officina dei Materiali è un ente che fa parte del CNR e ha sede al Sincrotrone di Trieste. Si occupa dello studio e lo sviluppo e la caratterizzazione di materiali, sia per le industrie che per la ricerca. In particolare è dotato presso il Laboratorio di Tecnologie Avanzate, Superfici e Catalisi (TASC) di un microscopio elettronico a scansione (SEM). È uno strumento che di solito è usato in maniera complementare ad altri e permette di avere immagini dei materiali. Ad esempio quando costruisci dei materiali, col SEM puoi verificare se li hai effettivamente costruiti bene.
La ricerca presentata dal tuo team riguarda l’ambito del riconoscimento immagini. Questa in realtà è una tecnica che negli ultimi anni è sempre più usata e ha trovato molte applicazioni. Perché vi siete dedicati anche voi a questo campo?
In effetti sentivamo di voler rimanere anche noi attuali e sfruttare queste nuove tecnologie per integrare il data repository con uno strumento che ancora mancava alle nanoscienze. In questo campo di ricerca il problema è che viene prodotto un enorme numero di immagini. Queste immagini hanno dei metadati, ovvero dati che costituiscono una sorta etichetta per le immagini indicando le loro principali caratteristiche rendendo possibile cercarle e selezionarle. A volte però nella loro scrittura manca un criterio uniformità che sia orientato a una facile ricerca. Si finisce così per produrre tutti questi dati e non sapere poi come andarli a ricercare nel data repository. Nel progetto per fare un motore di ricerca per metadati volevamo aggiungere anche che cosa fosse l’oggetto stesso, inserire cioè una caratterizzazione visuale dell’oggetto stesso. In questo modo, un ricercatore che voglia individuare tutti i nanotubi generati da tale strumento, con la ricerca per la categoria “nanotubo” li ritrova tutti. In pratica abbiamo riprodotto nelle nanoscienze il funzionamento di google immagini.
Per darti una stima, le immagini che ci sono state date dal TASC per sviluppare il sofware sono immagini raccolte in 5 anni da un centinaio di utenti e sono ben 150 000 per un totale di 200 GB di memoria. Classificarle manualmente è difficoltoso e senza metodi automatici diventa difficile gestirle. Inoltre ci può essere anche il problema della classificazione secondo criteri soggettivi: se noi lasciamo il compito di definire il tipo di oggetto in mano all’utente è facile che ciò venga svolto in maniera non uniforme. C’è invece la necessità di definire un certo numero di categorie in cui collocare le immagini secondo determinati standard. Attraverso il software che abbiamo sviluppato questa classificazione sarà fatta in automatico. Per il momento in realtà è semiautomatica poiché essendo in fase di test è presente un meccanismo di conferma. Ciò vuol dire che l’utente vede la predizione della categoria da parte del programma, ma può decidere di cambiarla se non risponde alle sue esigenze.
Come avete proceduto nella costruzione del software e quali risultati avete ottenuto?
Il primo step è stato quello di prendere parte delle immagini forniteci dal TASC, guardarle una per una e classificarle a mano. Parliamo di oltre 20.000 immagini, circa un decimo di quelle che abbiamo. Abbiamo quindi deciso in quante categorie accorparle e poi le abbiamo inserite man mano in queste categorie. Ovviamente questo è stato fatto con la consulenza e la supervisione di nanoscienziati. Successivamente per ogni categoria l’80% di immagini è stato destinato per l’allenamento di una rete neurale, il 10% per la validazione della rete e un altro 10% per il test. In seguito abbiamo analizzato e testato varie architetture di reti neurali disponibili e ne abbiamo scelto una sviluppata da Google poiché ci dava prestazioni migliori.
Le reti neurali sono degli insiemi di fasi di calcolo ognuna delle quali compie una specifica operazione venendo attivata e regolata da una serie di parametri da definire in base alle esigenze. Quella di Google che abbiamo scelto si chiama Inception V3 ed è in opensource. Abbiamo quindi fatto un training di questa rete, ossia l’abbiamo allenata a riconoscere le immagini attraverso un cosiddetto algoritmo di machine learning, cioè una sequenza di calcoli che permette alla rete di calibrarsi modificando progressivamente i parametri che la regolano fino a che non ottiene risultati corretti. Questa operazione è stata fatta prendendo però un checkpoint che vuol dire che la rete non è stata allenata da zero ma parte con dei parametri già fissati. La rete di Google infatti è già allenata su un set di dati molto più completo del nostro e con molte più immagini. Questa operazione si chiama transfer learning e consente di applicare al nostro campione le conoscenze che la rete ha già appreso su un altro campione riducendo la fase di allenamento solo ad alcuni parametri di interesse. In pratica abbiamo usato una rete che ha imparato a riconoscere immagini e la abbiamo allenata a riconoscere le immagini SEM.
Facendo vari confronti abbiamo appurato che i vantaggi principali dell’usare il transfer learning sono innanzitutto un tempo ridotto, minuti, al massimo ore, per ottenere una rete allenata ovvero un modello finito in grado di classificare immagini. Per confronto allenare una rete da zero richiede giorni se non settimane. Un altro dei vantaggi che si hanno – e che è stato anche il motivo principale per cui noi siamo partiti dal fare un retraining e non un allenamento da zero – è stato il fatto che occorrono meno immagini proprio perché la rete non deve ricalibrare tutti i parametri ma solo quelli specifici di interesse. In questo modo invece ne basta un numero relativamente piccolo e ciò è fondamentale visto che noi ne abbiamo avute a disposizione all’incirca un migliaio per categoria, ma per alcune anche molte meno. In ogni caso, anche con tempi ridotti e un basso numero di immagini, le prestazioni ottenute sono molto buone. Siamo infatti arrivato al 90% di accuratezza: vuol dire che su 100 immagini 90 sono correttamente classificate.
Questo software verrà inserito all’interno del processo generale di gestione dei dati sulle nanoscienze sviluppato per le strutture del NFFA Europe. L’intera procedura farà sì che, nel momento in cui le immagini prodotte nei vari esperimenti verranno salvate, avranno automaticamente tra i metadati non solo informazioni tecniche come chi ha fatto la misura, quando, su che strumento, con che energia, quale materiale è stato analizzato, ma anche una classificazione visuale del tipo di nanostruttura. I metadati così uniformati saranno immagazzinati in un unico repository che consentirà di ricercare le immagini di interesse indirizzandoti alle varie banche dati dove sono immagazzinate. Questo renderà eventuali ulteriori analisi o la verifica dei risultati di un esperimento molto più semplici, veloci e affidabili.
Un’ultima domanda. L’ingegneria informatica è un campo di lavoro considerato in genere molto maschile. È davvero così e ciò ti ha mai creato problemi?
Il mio ambiente di lavoro è totalmente maschile: almeno per quanto riguarda la vita in ufficio sono circondata solo da uomini. Se si considera il gruppo più ampio del NFFA Europe c’è comunque una bassa percentuale femminile. Fortunatamente, tranne rarissime incomprensioni iniziali, la cosa non mi ha mai creato problemi. Diciamo che mi so far valere.
Leggi anche: Le 11 dimensioni del nostro super-complesso cervello
Pubblicato con licenza Creative Commons Attribuzione-Non opere derivate 2.5 Italia. ![]()