Come vedono le intelligenze artificiali?
Negli ultimi anni ci sono stati notevoli progressi nello sviluppo di intelligenze artificiali, ossia di programmi in grado di interagire in maniera efficiente con l’ambiente circostante per risolvere problemi o situazioni nuove.
Nel costruire un programma di intelligenza artificiale ci si basa sull’assunto che i processi cognitivi siano fenomeni chimico-fisici misurabili in modo oggettivo (quello che viene definito approccio riduzionistico allo studio della cognizione), e che questi fenomeni siano espressione di eventi computazionali, ossia di calcoli, che in quanto tali possono essere riprodotti anche al di fuori del nostro cervello.

In questo ambito di ricerca è possibile quindi fare una prima distinzione sul tipo di intelligenza artificiale con cui abbiamo a che fare: parleremo quindi di intelligenze artificiali deboli nel caso di programmi in grado di risolvere problemi specifici troppo complessi o ripetitivi (come ad esempio l’elaborazione dei dati necessaria per effettuare delle previsioni meteo); la definizione di intelligenza artificiale forte invece presuppone la riproduzione artificiale della mente umana, un obiettivo dalla cui realizzazione siamo lontanissimi. E che, almeno secondo gli esperti, potrebbe addirittura non essere mai raggiunto. Questo anche se già ad oggi esistono programmi di intelligenza artificiale debole che sembrano esprimere un’intelligenza forte, come i software in grado di battere i campioni del mondo umani in diversi giochi da tavolo, imparando dai propri sbagli e diventando così sempre più abili, partita dopo partita. Per capire il livello di complessità del sistema computazionale che si vuole riprodurre si pensi ad esempio a un’abilità, comune a moltissimi animali (anche quelli che consideriamo meno intelligenti, ossia evoluzionisticamente più lontani da noi), apparentemente banale ma che risulta molto difficile da riprodurre in una macchina: la visione.
Cosa avviene nel cervello quando vediamo
Quando i fotorecettori posti sulla retina vengono colpiti da uno stimolo (cioè dalla luce) inviano un segnale, attraverso il nervo ottico, alla corteccia visiva primaria. Quest’area del cervello, posta nel lobo occipitale (a livello della nuca), è costituita da neuroni che producono del potenziale d’azione (o, detto altrimenti, “scaricano”) quando gli stimoli visivi appaiono nel loro campo recettoriale. In quest’area i neuroni codificano e discriminano cambiamenti anche minimi a livello di orientamento spaziale e di colori, in un crescendo di complessità che porta, alla fine, a vedere un oggetto identificandone bordi, contorni e caratteristiche principali.
Vedere un oggetto in termini di forme e colori è un’informazione necessaria, ma di certo non sufficiente: è a questo punto, infatti, che intervengono le aree associative visive (la corteccia visiva secondaria, terziaria e quaternaria, Fig. 1). Queste aree sono responsabili del riconoscimento e dell’interpretazione dei segnali provenienti dalla corteccia visiva primaria, e ci permettono di “dare un senso” a quello che vediamo, anche grazie alle informazioni apprese e memorizzate da esperienze precedenti.
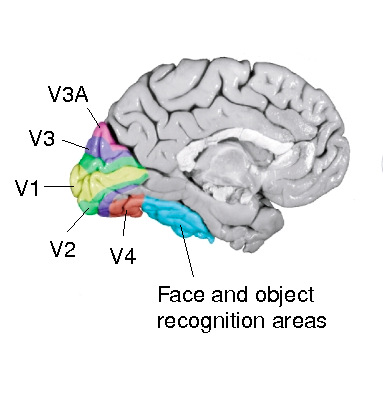
A questo livello, cioè dove si realizza l’integrazione di processi percettivi, attentivi e mnemonici, avviene quindi il riconoscimento dell’oggetto, la parte più intelligente del processo visivo. Il nostro cervello lo attua attraverso l’estrazione delle caratteristiche fondamentali di quello che stiamo osservando, per poi confrontarle con pattern di stimolazione incontrati in precedenza. Prendiamo questa immagine:

Tutti noi riconosciamo in essa una sedia, anche se non abbiamo mai visto questo particolare oggetto prima d’ora. Tuttavia riusciamo ad estrarre alcune caratteristiche dell’oggetto (ha quattro gambe, una seduta, uno schienale) che ci permettono di categorizzarla come tale. In maniera implicita e inconsapevole abbiamo risolto anche un problema – assolutamente non banale dal punto di vista cognitivo – che è quello dell’invarianza, ossia di riconoscere l’oggetto a prescindere dal suo orientamento nello spazio e dal punto di vista da cui lo sto osservando.
Riprodurre un modello complesso
È chiaro che alla base della visione c’è quindi un modello di organizzazione gerarchica, molto complesso da riprodurre in un algoritmo. Come fare, quindi, per far sì che un software veda e riconosca un oggetto? Il primo passo è quello di descrivere in modo analitico, e quindi riprodurre, il funzionamento di un neurone. Bisogna quindi creare delle unità base che si attivino o si inibiscano in risposta all’integrazione dei segnali provenienti da altre unità che sono connesse ad essa.
Successivamente, i neuroni devono essere organizzati in reti neurali multistrato che emulino la struttura gerarchica del riconoscimento visivo (ad esempio della sedia di prima). Avremo quindi innanzitutto uno strato di input, costituito neuroni artificiali attivati da dati, come i pixel di un’immagine; una serie di strati intermedi, nascosti, che elaborano queste informazioni; uno strato di output che fornisca la risposta finale (“oggetto riconosciuto come sedia”).
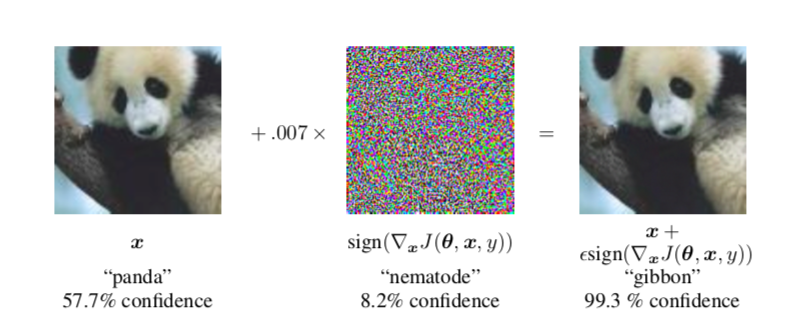
Nel corso degli ultimi 6-7 anni queste reti, denominate hierarchical convolutional neural networks (HCNN) sono passate da avere poche unità di strati fino alle centinaia di ora, e vengono addestrate al riconoscimento di oggetti specifici attraverso l’utilizzo di milioni di immagini. Da un “classico” sistema di machine learning si è passato a quello che viene definito deep learning. L’aspetto forse più strano di questi sistemi è che essi non sono in grado di fornire una spiegazione adeguata sul come sono arrivati a fornire un determinato output, ossia una descrizione degli stati intermedi: per questo motivo questo ci si riferisce a questo problema come il problema della scatola nera. Ciò risulta di particolare importanza sia per sviluppare reti neurali sempre più efficienti, sia per capire dove si stia sbagliando quando qualcosa non funziona. Anche se a volte il riconoscimento visivo eseguito dalle reti neurali deep ci appare sbalorditivo, esse sono in realtà molto fragili: se in situazioni ottimali il riconoscimento avviene in modo corretto, basta un leggerissimo rumore di fondo, impercettibile per la visione umana, per mandarle letteralmente in tilt.
Leggi anche: L’intelligenza artificiale del domani
Articolo pubblicato con licenza Creative Commons Attribuzione-Non opere derivate 2.5 Italia. ![]()
Immagine: Pixabay